
第四十届AAAI人工智能国际会议(The 40th AAAI Conference on Artificial Intelligence,AAAI 2026)将于2026年1月20日至27日在新加坡博览中心隆重举办。本届会议以“大语言模型深度逻辑推理”为核心专题,并围绕跨模态融合、AI伦理与安全等前沿方向展开,汇集了全球顶尖研究机构的学者,共同探讨人工智能领域的前沿挑战与发展方向,其中多模态一致性、模型可信性等议题成为会议关注的焦点。AAAI 作为人工智能领域最具影响力的国际顶级会议之一,与NeurIPS、ICML并称为全球AI三大旗舰会议,也是中国计算机学会(CCF)推荐的A类国际会议。本届会议共收到来自全球的高水平投稿,最终录用率仅为17.6%,竞争异常激烈,充分体现了其严苛的学术标准与国际认可度。
我院师生合作论文《ModalSyncSum: Synchronizing Image and Text for Reliable Summary Generation》被AAAI 2026录用为长文并进行报告。论文第一作者为学院2023级在读硕士研究生陈宣齐同学,论文通讯作者为其导师蒋盛益教授。
论文概述:多模态摘要(Multimodal Summarization with Multimodal Output,MSMO)任务旨在同时生成文本摘要与图像描述,以实现跨模态信息的综合表达。然而,现有大规模多模态模型(如GPT-4o、LLaMA-3、Grok-3 等)在该任务中普遍存在视觉-文本对齐不足、图像误解、跨模态幻觉等问题,导致生成的摘要在事实一致性与图文对应上存在偏差。为解决上述痛点,论文提出了一种面向多模态一致性约束的摘要生成框架ModalSyncSum,通过显式引入图像语义验证机制,提高摘要的视觉可信度与跨模态一致性。
该框架无需对大规模多模态模型进行微调,核心包含三个核心模块:其一为图像感知信息抽取模块,基于CLIP实现图文语义匹配,从原文中筛选与图像关联性最强的句子,进而生成精准的候选描述;其二是基于视觉问答的描述校验模块,借助BLIP提取图像中的事实信息,通过构造问题-回答对验证候选描述与图像内容的一致性,有效抑制幻觉生成;其三为命名实体引导的摘要一致性验证模块,通过自动生成实体级QA对生成摘要进行逐项事实核验,并驱动语言模型完成自我修正,确保摘要与原文及图像内容完全一致。此外,论文还提出了全新的多模态评价指标 M3AS,该指标从图像信息覆盖度、图文对齐度及跨模态一致性三个维度综合评估摘要质量,弥补了ROUGE、BLEU等传统文本评价指标无法衡量视觉语义关联的缺陷。
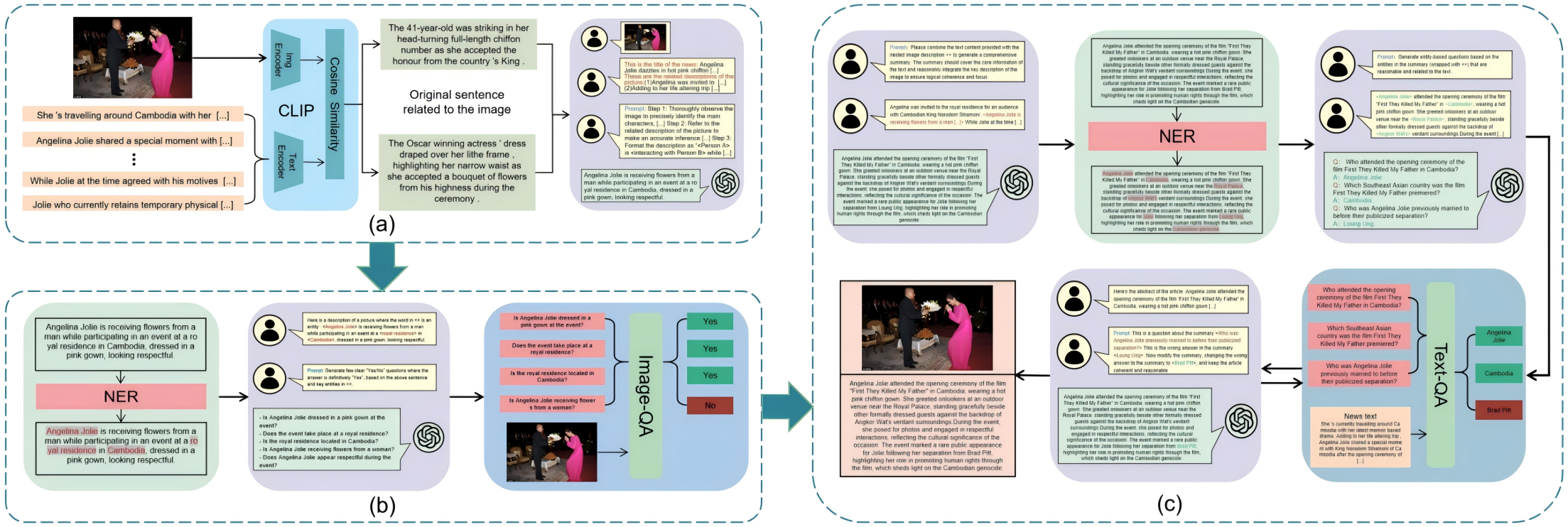
图1: ModalSyncSum流程图
在MSMO、M3LS与E-Liputan等多个权威数据集上的实验结果显示,ModalSyncSum在ROUGE、BLEU、BERTScore等主流指标上均取得显著提升,其中BLEU指标最高提升21.95%;在人工评价中,M3AS与人工判断的一致性显著高于现有自动指标,充分验证了该模型在抑制多模态幻觉与提升图文一致性方面的有效性,为构建高可靠性的多模态摘要系统提供了新的解决思路。
初稿:陈宣齐
复审:蒋盛益
终审:王连喜





